
Deeper
07 Oct 2025
Try it at deeper.lovable.app.
My childhood friend pitched me this app idea. His friend pitched it to him. And she probably made it up, so the chain stops.
How are we pitching it today? “Did you ever want to know, who’s the jerk? Let our app tell you!”
Naturally, that pitch isn’t for everyone. Here’s the longer version. You need to have a difficult conversation. You sit across from your partner and start. But something goes wrong. You spiral into unproductive word salad, blame, defense, and flinging of hot soup. Not good.
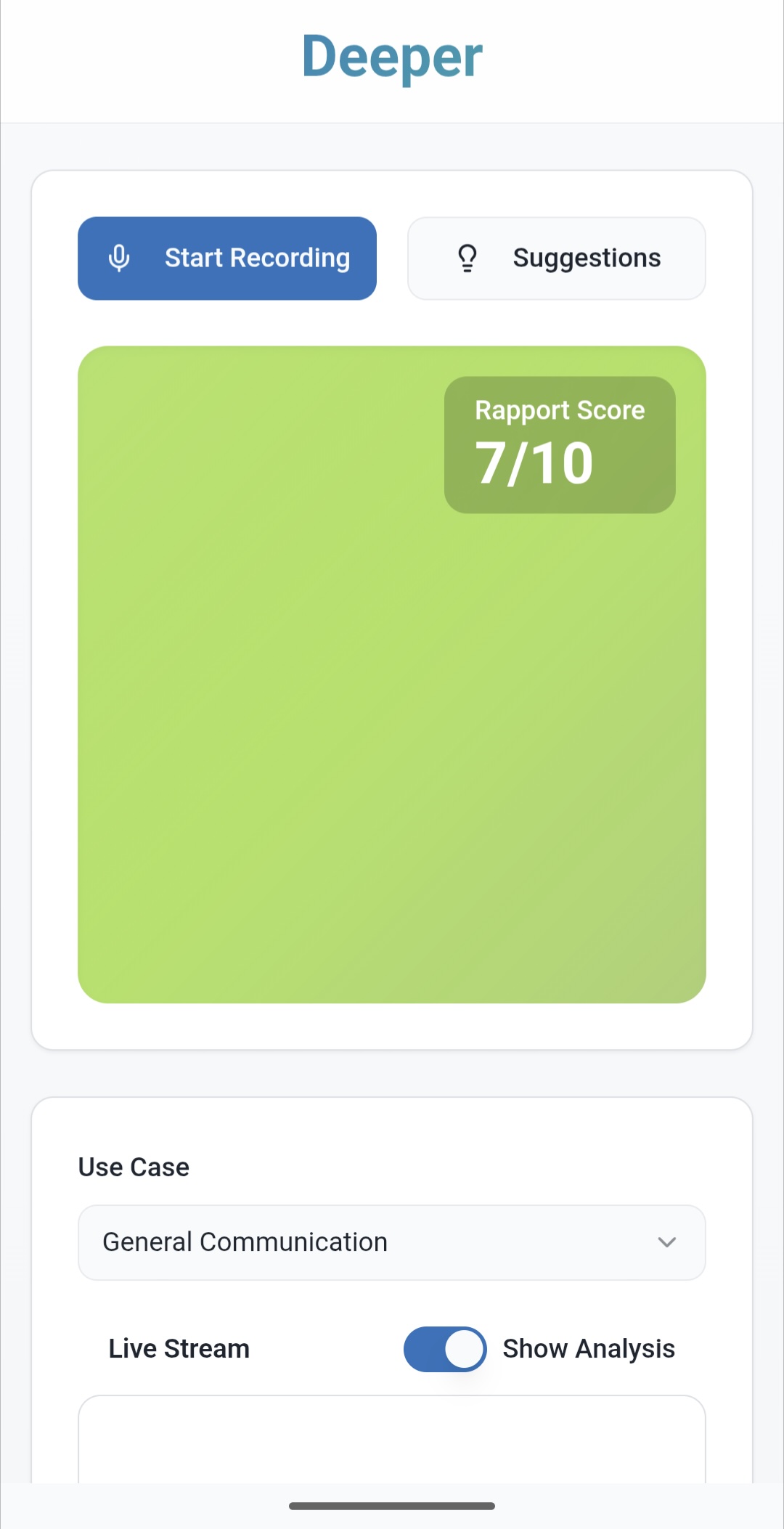
Enter Deeper. You start the app and leave it on the table. The app helps you stay connected, to retain mutual understanding, and to go deeper. How does it do it? It monitors the rapport between the participants and alerts when your connection strains. If your rapport drops, the screen paints red. You can then prompt Deeper for advice by tapping the screen.
Deeper is driven by the tenants of Non Violent Communication or NVC and mindful connection. Other frameworks may be available in the future. As such, Deeper will flag when the two of you stray from mutual understanding or slide into unproductive or adversarial patterns.
How We Built It
The basic architecture is simple. Capture audio of a conversation happening in real time. Transcribe it to text in real time. Send the transcript to an LLM for analysis in real-ish time. Alert the user based on LLM results.
Easy enough. Get to work.
I surveyed the landscape of LLMs willing to accept audio. There are many transcription services, but most are intended for batch processing. You upload a file, it transcribes it, you get the text results. This creates challenges for our use case. Chunking a live audio stream adds complexity. Context helps, so you’ll probably want to overlap the chunks, increasing data transfer.
Recently several products became available that accept live audio. Most of these are intended for agents. Bad fit. You use voice to tell an LLM what to do. We want to provide voice data to an LLM and tell the LLM what to do about it. No good. But among the options were several which take live audio and give live transcripts. Almost there!
The final piece was diarization. Diarization is speaker labelling. Very important for our use case where multiple speakers’ replicas interleave. Here we had a bit of a false start. AssemblyAI looked very promising. It supported streaming transcription and diarization. But not together. Good job, Yury. A quick rewrite later, we’re getting streaming diarized transcripts from Deepgram.
Halfway there. Time for a detour.
What are you going to call an app that helps you be kinder in difficult interactions? I have an idea. “No step on fren,” of course! Semi-accepted. Pasha creates a logo.
I won’t explain the joke. If you chuckled, just know: I see you.
Next we need to put the transcript into a prompt for an LLM, tell it how helpful it’s about to become, how it is to respond, and send it off. Which LLM, you ask. Honestly, I have no idea. Let’s try them all. Using a wrapper like LiteLLM allows us to talk to a bunch of models and products via a single interface as well as to receive structured, well-formed output.
We have lift-off! At this point we can demonstrate live transcription, transcript analysis, and suggestions. But we don’t have a frontend. There’s a challenge here. Neither of us is an experienced UI developer. I’m what you might call “UI-stupid.” But I do have an eye for shit code. That’s an advantage of sorts. I’m really fun at parties.
A few prompts in Lovable and we have both a UI and a server with a websocket. We rip out the server completely and clean up the most obvious AI slop in the UI. Easy enough. Adjust the APIs to match, and we have a working app.
Websockets present a new challenge: we need persistent connections to individual backends and I can’t control this in Lovable. Enter Render. The free tier will put your server to sleep when inactive, but we’re not ready to complain about this yet.
We have the prototype at deeper.lovable.app.